
Language Resources
The Impact Centre of Competence provides historical and named-entities lexica for the following languages. In addition, we offer access to the different corpora.
WHAT IS A LEXICON?
A lexicon is a structured, machine-usable repository of relevant linguistic knowledge about words in a language. A lexicon will contain historical variants (orthographical variants, inflected forms) and link them to a corresponding dictionary form in modern spelling (known as a ‘modern lemma’).
Historical Lexica

Bulgarian Lexicon
The current lexicon consists of 28,857 lexical entries.

Czech Lexicon
The period covered by the Historical Lexicon of Czech is 1800 – 1900.

Dutch Lexicon
The period covered by the Historical Lexicon of Dutch is 1600 – 1940.

German Lexicon
The German lexicon consists of 510 texts including different genres.
Corpora
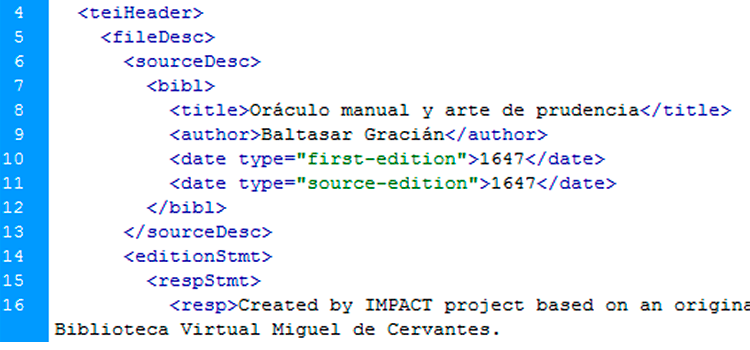
IMPACT-es Diachronic Corpus
IMPACT-es diachronic corpus of historical Spanish compiles over one hundred books. A complementary lexicon which links more than 10 thousand lemmas.
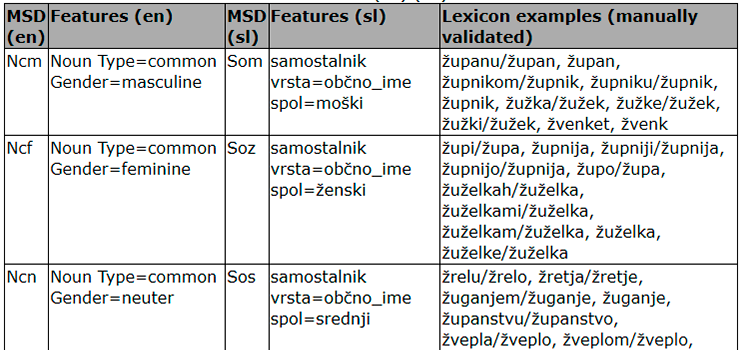
IMP Slovene Corpora
The reference corpus of historical Slovene goo300k contains the text from 1,100 pages sampled from the IMP collection with hand-validated linguistic annotation.